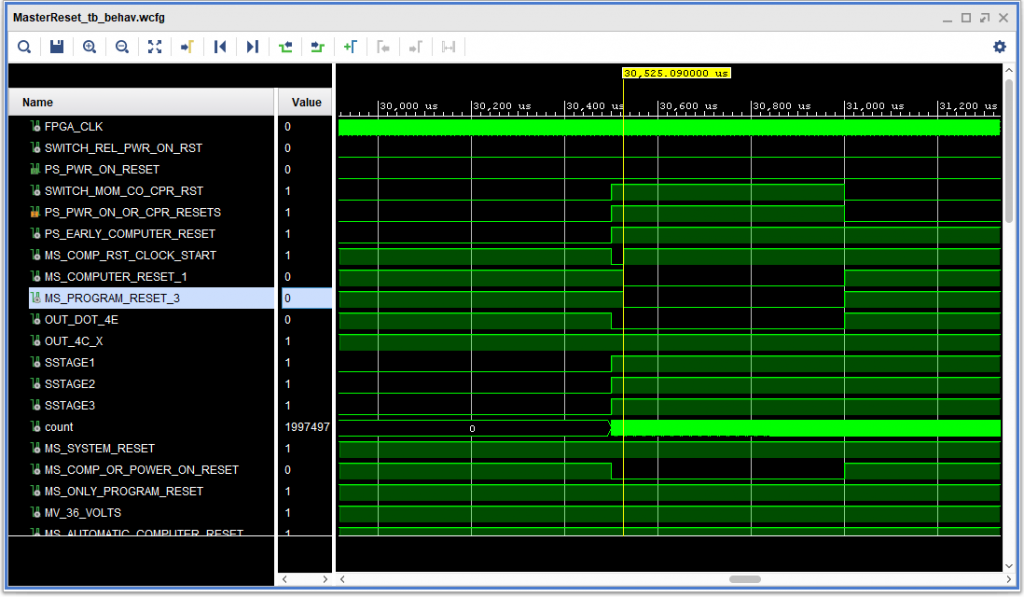
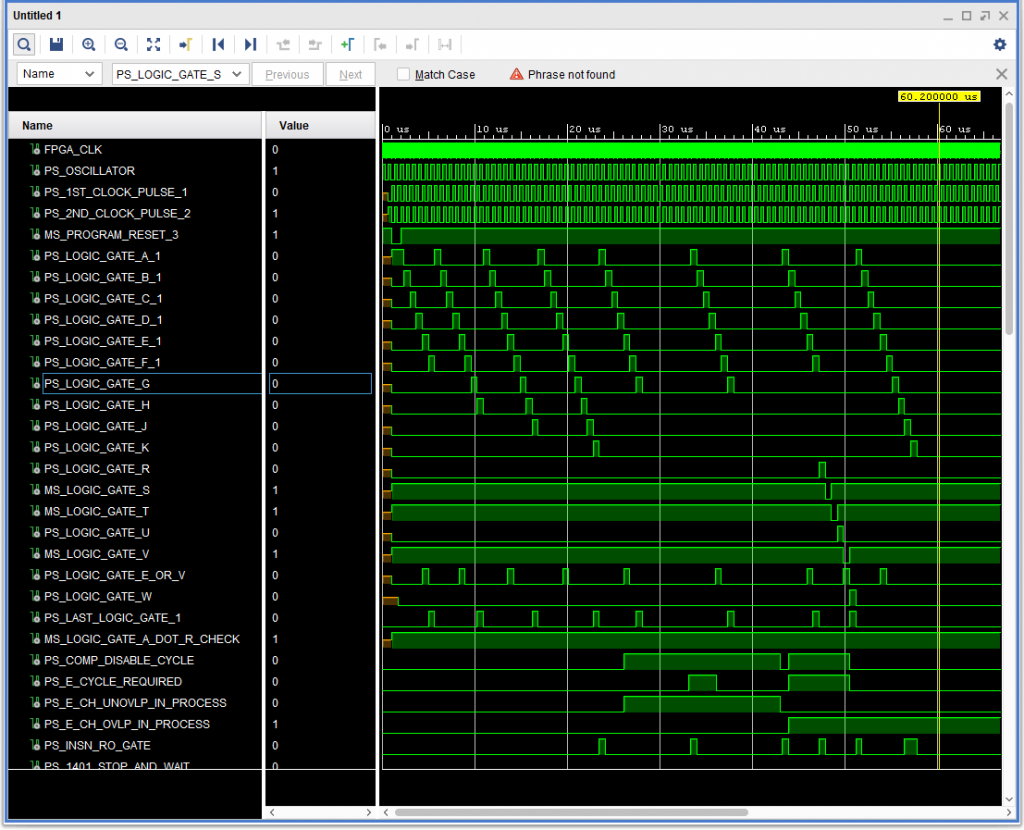
As part of my project to create a Field Programmable Gate Array implementation (FPGA) of the IBM 1410 Data Processing System based on Automated Logic Diagrams (ALDs), I decided to look at using the Instructional Logic Diagrams (ILDs) to guide my testing, rather than using the ALDs directly.
The ILDs are written completely in “positive logic”. Going in, I sort of expected a pretty imperfect match – that the ILDs would not have all the signals, and be somewhat superficial in their treatment of the logic. For the IBM 1410, the circuits were:
- AND
- OR
- Inverter
- Indicator (Lamp)
- Single Shot
- Latch (Reset/Set)
- Trigger (Flip Flop)
To my surprise I found that the ILDs are very accurate, and a great testing guide, providing a second view of the logic – a kind of redundancy check against my entry of ALD data into my system. They are good enough that they have given me considerable confidence that I can use them to help “fill in the blanks” related to the handful of ALD pages I am missing, and also for some of the IBM 1414 peripheral controllers for which I do not have ALDs.
Updated 6/28/2020, I discovered that not all of the ALDs are represented in the ILDs. I also had an interesting case where I thought, for a while, an ALD and the ILD that represents it were mismatched, but I was incorrect – the ILD matched the logic perfectly.
In 1962 IBM published an article in the IEEE Transactions “Information Processing — from Engineering Drawing to Manufacture” by R. K. Grim that describes how the data the ended up generated ALDs was entered and the ALDs produced, but it does not mention where the ILDs come from. They are definitely artwork – not machine generated per se. The article did not address ILDs.
I have corresponded with IBM to see if they might have, in their archives, the data from these 1960s era engineering systems, but it seems that they do not (or have lost the pointers to them.)
It seems that the SMS automation was first done using an IBM 709, then they later added IBM 7090 and IBM 1401 systems (which of course could not have been there for the original design of the IBM 7090 and 1401, which used the SMS system), using tape files. The article also describes future plans to use a 1301 disk drive attached to an IBM 1410 for remote (tele-processing) access (which was supported by the IBM 1410-PR155 operating system.
The accuracy of the ILDs is such that I expect that they evolved along with the design of the machine and entry of the data used for the ALDs. I’d expect that doing it after the fact, from the ALDs, would be quite error prone — besides the one difference I have found is in the signal names, which do not always exactly match those used in the ALDs, but are close enough that the intent is obvious. But I don’t know the timing: which came first — the ILDs or the ALDs, or did they perhaps begin together in some form and co-evolve?
In summary, it seems to me that one could do a pretty decent positive logic implementation of IBM machines of that era using these ILDs. This was a real eye-opener.